
Solutions in Water Environment
for People and Planet
In the early 1980s, the Activated Sludge Model Number 1 (ASM1)has given us a decade of experience in applying these models and demonstrating their maturity in the design and operation of wastewater treatment plants, but these models have reached their limits with respect to complexity and application accuracy.
A good example is the N2Despite the many extensions of ASMs that have been proposed to describe the production dynamics of activated sludge plants, these models are still too complex and not yet validated. The paper in this perspective presents a new vision to advance process modeling by explicitly incorporating information about microbial communities measured by molecular data in activated sludge models.
In this new area of research, we propose to capitalize on the synergies between the rich molecular data from advanced gene sequencing technologies and their integration with process engineering models and artificial intelligence. This is an interdisciplinary area of research that brings together two separate fields of environmental biotechnology to work with the modeling and engineering communities to enable new understanding and model-based engineering of future sustainable WWTPs.
Wastewater treatment is a complex process that uses a combination of physical, chemical, and biological unit operations to remove contaminants to a sufficient quality before being discharged into the receiving environment.
WWTPs have been in use for more than 100 years since the discovery of the activated sludge process, which has resulted in many mature technologies and process concepts being implemented in practice.
Today, the wastewater treatment sector is witnessing a growing number of initiatives (e.g. digital water, water-energy nexus, circular economy, water scarcity and deteriorating water quality due to emerging contaminants such as trace pollutants and climate change).
These powerful initiatives are set to fundamentally change the basic concept of WWTP.
For example, wastewater is no longer perceived as a problem, but increasingly as a potential resource from which water, energy, and nutrients can be recovered.
In addition, energy, chemical, and process-related greenhouse gas emissions (especially N2O) need to be considered at WWTPs. Currently, the design and operation of treatment plants rely on best practices and heuristic approaches, which are complemented by the use of process models to simulate and evaluate different alternatives.
In this regard, the introduction of the Activated Sludge Model No. 1 (ASM1) in the early 1980s provided a decade of experience in calibrating and applying the model and demonstrating its maturity for application to the design and operation of power plants.
However, these models have reached their limits in terms of complexity and application accuracy and cannot comprehensively describe process performance parameters.
This is essential to realizing the full potential of digitization to enable model-based engineering and, consequently, to achieve sustainable WWTP operations. Therefore, we believe that a radical change in the fundamental nature of advancing process modeling is needed in the wastewater treatment modeling and engineering community.
The central hypothesis of this new vision is based on the following premise.
(1) There is a strong conviction that data alone may not contain enough information to achieve useful models for digital applications.
(2) The current mechanical model is not sufficient, especially for N2Can't explain emerging sustainability issues in plants, such as O dynamics. Unlike social sciences/media where data is actually very rich (high volume/high veracity). Data from engineering systems such as WWTPs, which are designed and operated to provide reliable and stable performance, have limited information (quality and quantity) compared to the volume of data in social media.
Therefore, it is necessary to take full advantage of previous scientific and engineering knowledge that is well summarized in mechanistic models. Creating advanced predictive models for digital applications in WWTPs requires a multidisciplinary approach where in-depth process knowledge is combined with deep learning from process data.
With this research concept, we propose that for the first time it will be possible to include molecular data on microbial communities directly into process models. Modern molecular tools to measure microbial communities (relative abundance of species)
However, these valuable data have never been used directly for process modeling. Below, we outline and expand on the evidence that points to the current challenges and limitations of activated sludge models (ASMs), why they cannot be provided by big data analytics alone, and the need for an interdisciplinary research area to advance the future of activated sludge. Modeling.
The activated sludge process is the most commonly used technology in wastewater treatment plants. Research on the design and operation of activated sludge systems is traditionally supported by two communities.
operational taxonomic units (OTUs), metatranscriptomics, proteomics, metabolomics, etc.) to support the microbial communities responsible for nutrient removal in plants (who they are and what they do), and (b) process design, modeling, and control communities that work in conjunction with process models and are based on existing process data (e.g., influent COD fractions (SS, XS, SI, and XI), nitrogen (NH4 , NO3 , NO2 -N, TKN), PO4, Develop and validate new models and technologies to support the design and operation of power plants (TP, MLSS, VSS, BOD, etc.).
These multidimensional data collected at different scales (micro-scale at the level of microbial communities vs. macro/global-scale process data at the level of plants) are clearly complementary to understanding processes, but to date, these two multiscale and diverse sets of process data are yet to be integrated and jointly interpreted.
For example, the microbial community underpins biological conversion in WWTPs and is therefore key to plant performance (from effluent nitrogen, phosphorus, and COD quality to process-related GHG emissions) was not explicitly/directly included in the model.
On the other hand,17 . These developments have led to the introduction of the N2In researching new processes to understand the pathways responsible for O emissions, we have gained deeper insight into understanding the fundamental role and function of microbial communities, not only in the laboratory, but also in full-scale WWTPs18 .
However, these valuable data have not been integrated into process engineering applications, and this remains a large gap in the 2020s. One of the reasons for this is that the modeling frameworks currently used are not flexible enough to integrate such heterogeneous molecular data for different microbial communities.
The current process design and operation paradigm is highly process expert knowledge-driven and supported by commercial process simulators that can evaluate and simulate a wide variety of process configurations. In fact, to support current engineering solutions, process models and simulations are essential tools that are widely used in the community.
For process modeling, ASMs have been widely successful and extensively used. These models (e.g., ADM1, ASM1, ASM2d, Biowin ® models, SUMO ® models, etc.) are mechanistic and have provided significant benefits for design and operational issues. In addition, knowledge-based and model-based environmental decision support tools have been proposed.
It supports design engineers in designing/revamping processes to improve their work. However, it still has two fundamental drawbacks.
(1) Limitations of current mechanical models: Process models that support the evaluation of WWTP solutions cannot account for an important sustainability metric/performance of the plant, namely N2O emissions.
(2) Biological communities are responsible for the primary transformation and removal of contaminants, but are not included/integrated into process engineering practices from operations to design work.
In particular, in the field of process modeling, current academic research is producing increasingly complex and specialized models.
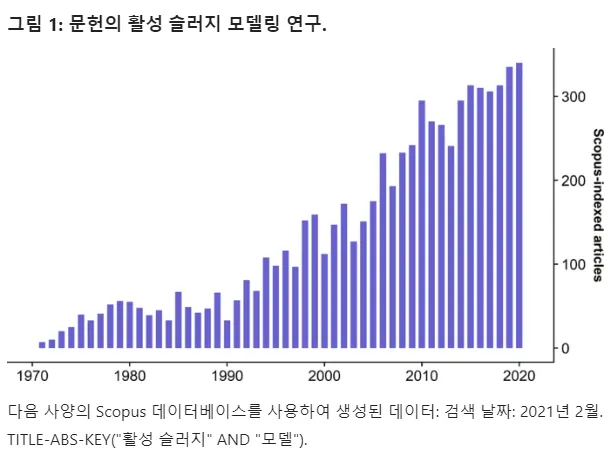
Figure 1 shows the continued interest in research using these models. These models, which are mostly based on extensions of ASM models to describe nitrogen, phosphorus, and COD removal performance in plants, are not well suited for process design and operational applications due to numerical complexity and validation issues.
The validation problem arises partly from the given structure of the model as well as from the available process data used for model parameter estimation (which is limited). Several studies have systematically analyzed the identifiability of such models.
Considering typical plant data collected in intensive measurement campaigns, including our own research, we have shown that out of 60+ model parameters, only a small number (6-10 parameter subsets) can be uniquely estimated from the data.
They have already been recognized by the calibration protocol. The remaining model parameters must be fixed or assumed when applying these models to simulate an activated sludge plant.
While uncertainties in model parameters can be accounted for and design and operational assessments can be made, key issues remain regarding defining uncertainty ranges for model parameters that exhibit a wide range of variability, as investigated by Sin et al.
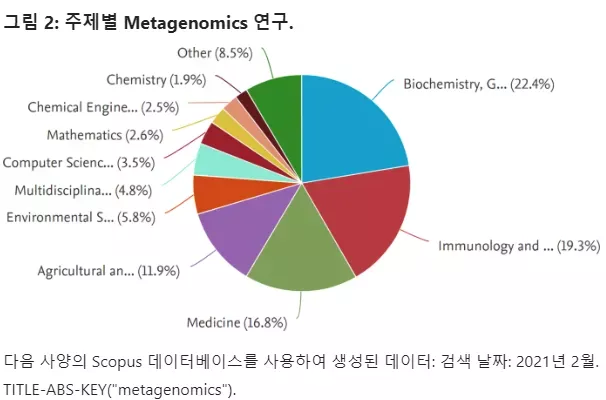
The research field of metagenomics examines the genomic analysis of microbial DNA in environmental communities and has grown rapidly over the past 5-10 years, becoming one of the hottest scientific fields with more than 16,000 research articles indexed in Scopus (Figures 1 and 2).
– 미생물 생태, 진화 및 다양성에 상당한 진보를 가져옴 . 이 분야는 과학자들에게 샘플에 포함된 내용에 대한 사전 지식 없이도 샘플에서 미생물을 식별할 수 있는 시퀀싱 기반 메타게놈 검사 도구를 제공하여 의학, 환경 과학, 미생물 생태학, 미생물학, 및 폐수 공학(그림2).
Among these techniques, fluorescence in situ hybridization (FISH) is a low-throughput technique that can be used to look for specific genes of interest in DNA to identify specific microorganisms.
Quantitative PCR (qPCR) is sensitive, quantitative, and uses fluorescent dyes to monitor the amplification of target DNA, so you can assess only a few microorganisms at a time.
16S ribosomal RNA sequencing, on the other hand, targets the 16S rRNA gene, which is highly species specific and present in most microorganisms, making it a fast and inexpensive alternative to identify and categorize bacteria.
In addition to sequencing, characterization of the metatranscriptome (using mRNA sequencing) overcomes the shortcomings of metagenomic DNA-based analysis by providing the ability to distinguish between expressed and unexpressed genes to reflect true metabolic activity.
It is more expensive, but the data obtained is more informative, allowing you to model quantified metabolic activity.
One of the underlying reasons for this model validation and uncertainty issue is that these models use Monod kinetics to describe microbial growth.
A theoretical identifiability study already done in 1982 by Holmberg.
In a simple ash batch reactor already used to measure biomass activity (e.g., measuring substrate over time), a given perfect measurement (no noise) is not a unique estimate of yield, maximum growth rate, and biomass concentration.
Later, the respiration measurements and titrations used by Petersen et al. for the activity of nitrified activated sludge samples confirmed the same conclusion: instead of a unique parameter, only a combination of parameters can be uniquely identified, e.g. ((4.57-YA)/YA*μmax* X )). An important observation about this conclusion is that X (mgCOD/L) is a batch parameter defined to represent the active portion of the microbial group included in the experiment.
For example, in a nitrification activity study X is XAOO and XNOO classified as.
Represents ammonia-oxidizing organisms and nitrite-oxidizing organisms, respectively.
These examples can be extended to other microbial groups in the activated sludge, such as denitrifying heterotrophic organisms, phosphorus accumulating organisms, and glycogen accumulating organisms, all of which are hypothetically modeled with units mg COD/L as the state variable.
Eventually, these different parts of the biomass are indirectly inferred using full-scale measurements of normal simulations with the corresponding batch activity test sets or models.
Note the irony here that the biological community is represented as a pseudo-parameter of the model. In reality, there is no direct way to measure them.
Therefore, there is no independent experimental procedure to validate the simulated values of these biomass parts responsible for different functions in the plant without making assumptions and conversion factors (e.g. VSS to COD ratio, etc.).
Instead, these proportions of biomass are indirectly inferred from model-based fitting of measured activity to biomass (e.g., via NH depletion).
4 -N ratio during batch testing with nitrified activated sludge). Even with perfect activity measurements, the estimated values of these ratios are still linked to the model's yield and maximum growth rate parameters (as discussed above in Holmberg 35 and Petersen et al. 37).
If the modeling community is using While using XAttempts to describe the corresponding activities in WWTPs, the biological communities that study this process, use modern molecular probe techniques (e.g., metagenomics, qPCR, FISH, etc.) to identify which organisms (phylogenies), their relative abundance, and activities.
For example, many contaminants present in the influent (NH4-N to COD, etc.) in meta-transcriptomics analysis of protein gene expression.
The research field of metagenomics examines the genomic analysis of microbial DNA in environmental communities and has grown rapidly over the past 5-10 years, becoming one of the hottest scientific fields with more than 16,000 research articles indexed in Scopus (Figure 1). . and 2)
– 미생물 생태, 진화 및 다양성에 상당한 진보를 가져옴.
This field provides scientists with sequencing-based metagenomic screening tools that allow them to identify microorganisms in samples without prior knowledge of what the sample contains, enabling them to make important discoveries in medicine, environmental science, microbial ecology, microbiology, and wastewater engineering (Fig.2).
Among these techniques, fluorescence in situ hybridization (FISH) is a low-throughput technique that can be used to look for specific genes of interest in DNA to identify specific microorganisms.
Quantitative PCR (qPCR) is sensitive, quantitative, and uses fluorescent dyes to monitor the amplification of target DNA, so you can assess only a few microorganisms at a time.
16S ribosomal RNA sequencing, on the other hand, targets the 16S rRNA gene, which is highly species specific and present in most microorganisms, making it a fast and inexpensive alternative to identify and categorize bacteria.
In addition to sequencing, characterization of the metatranscriptome (using mRNA sequencing) overcomes the shortcomings of metagenomic DNA-based analysis by providing the ability to distinguish between expressed and unexpressed genes to reflect true metabolic activity.
It's more expensive.
However, the data obtained is more informative, allowing you to model quantified metabolic activity.
We were pioneers in applying these methods to activated sludge systems in wastewater treatment and invited the research community to help us understand what organisms are present in activated sludge and what they do there.
Using 16S rRNA gene sequencing technology in conjunction with microbial diversity analysis, we identified a core community of microorganisms actively present in the activated sludge.
Applying these methods generates very comprehensive information about the centuries-old activated sludge process.
Integrating this new knowledge of the frequency and diversity of these microbial communities with their dynamic profiles over space and time allows us to understand how N2It can support quantitative modeling of fundamental phenomena in wastewater treatment processes, such as O emissions. One possible way to integrate these molecular data (metagenomics) with ODE-based mathematical models is to utilize artificial intelligence techniques such as deep learning.
Recent applications of DNNs in various fields, from product/material design to property and process modeling, neural AI has shown promise, especially when presented with a wide range/disparate data sources in the form of text, images, and spectral data.
In this new field of research, we call for the study and synergistic integration of biological data with first-principles models of activated sludge systems and the machine learning (ML) branch of AI.
In fact, it is duly noted that what we propose here is not new per se, and hybrid modeling has been extensively studied for a variety of applications. For example, hybrid modeling in chemical engineering (crystallization, drying, milling, polymerization) and biochemical engineering (modeling of various fermentation processes, mainly from fungi to bacteria, yeast and mammalian cell cultures) and water treatment.
The initial motivation for hybrid modeling is to improve the predictions of the first-principles model to correct the errors/inaccuracies present in the mass and energy balances calculated by the mechanical model.
Various parametric hybrid model designs are proposed, e.g. parallel, series and multiple combinations. Hybrid models are also often used to predict complex process phenomena.
Otherwise, it is very difficult to describe mechanistically (e.g. cake formation in cross filtration units or the rate/dynamics of product formation in fermentation processes). The application of hybrid models in wastewater has been studied for both industries.and domestic wastewater treatment plants.
For example, integrating an ANN model to learn biological kinetic rates from process data in a mechanical (ASM2d) model using parallel combinations, similar to the application of an extended Kalman filter to learn wastewater COD, NH4 and PO4To improve the prediction of -3, the authors used a series of combinations that modeled the error of the mechanical model (ASM3g-Eawag) using a neural network model. The EKF learns from the errors in the model.
While these models offered the possibility of improving the fit to the data (the model's R 2, coefficient of determination), but for example for process control and operation.
More importantly, they failed to model the kinetic rates associated with more complex phenomena, such as P-elimination, for example. These previous studies show that using only process data and even hybrid modeling is not the answer on its own. Comprehensive process data is needed to explain them.
The example cited in this perspective paper, N2O 모델링과 관련하여 몇 가지 다른 메커니즘(예: 단일 경로 대 두 경로 모델 – AOB 탈질화 경로 및 불완전 하이드록실아민 산화 경로 모델)을 가진 ASM 모델의 많은 확장, 화학적 전환 등)이 제안되었다.
These models can be made to fit N 2 O data collected from a specific time period during calibration (i.e., by fine-tuning or fitting a subset of the model parameters), thanks to the many parameters introduced.
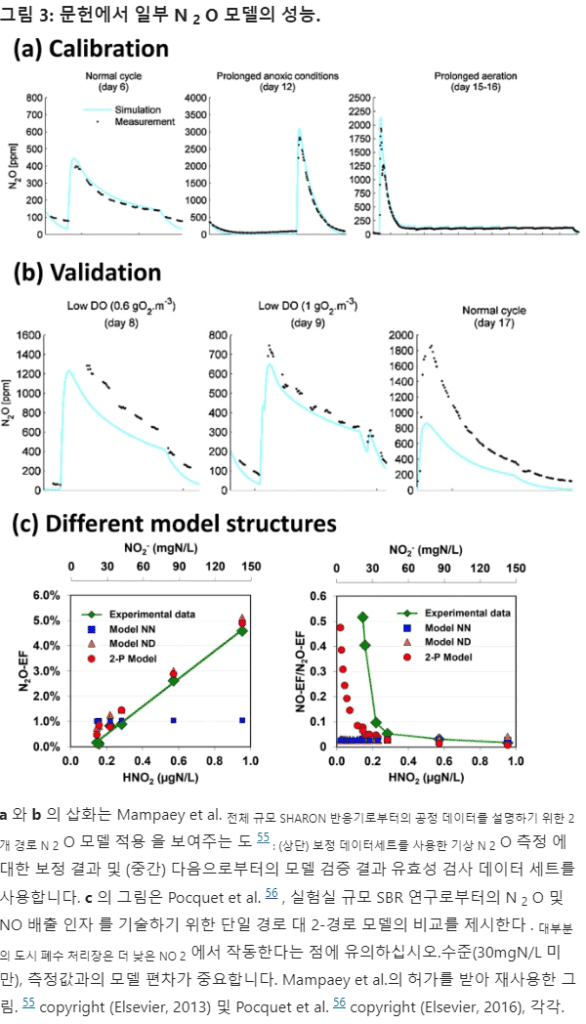
However, such models have been used, for example, by Mampaey et al. in N2O emission rate by 42%, which is easily falsified when confronted with other data sets that were not used in the calibration.
For example. Figure 3 presents a schematic to help visualize model performance between calibration and validation datasets as demonstrated in the study by Mampaey et al.
In practice, current mathematical models do not know a priori which metabolic pathways are the dominant contributors, and so the N2O emission factors may not be quantitatively accounted for.
Most municipal wastewater treatment plants are required to have lower NO2 in the following example.
Especially at levels where the failure of the model is notable (much lower than 30 mgN/L). In a way, the extended models have increased the number of parameters that need to be estimated from the same activity measurements, thus compounding the existing identifiability problems of these models. This makes their transferability and general applicability to process design and operation difficult and unpredictable, and therefore impossible.
On the other hand, the use of ML on process data was also applied, using PCA-based clustering techniques 57 This N2It has been shown that it can be used to identify operational situations that cause O emissions.
N using Support Vector Machines (SVM) as ML technology2
Cross-validation, even when describing data sets from relatively simple pilot-scale reactors R2 remains low, but can account for O emissions. In our own work with DNN 59, we found that cross-validation test data from the R 2 Use a deep learning network (DNN) with a high accuracy of up to 0.9 to determine N2O and demonstrated the possibility of explaining it.
While these models are useful for performing sensitivity analysis on inputs, the main issue here is that these purely data-driven models are not useful for process design and operational purposes.
Simply because of this data-driven model, the N2 changes/seasonal variations in N2O emissions again. In short, neither mechanical nor AI (ML) models alone can predict N2O claims that the data cannot be explained predictively.
Therefore, our opinion is that N 2 O emissions, as has been argued for CO2 emissions, is that neither the data itself nor current mechanistic models are sufficient to develop predictive models for emerging sustainability issues.
It is our belief that these models do not predictively describe the system due to the lack of integration of data directly related to the composition and activity of the microbial community.
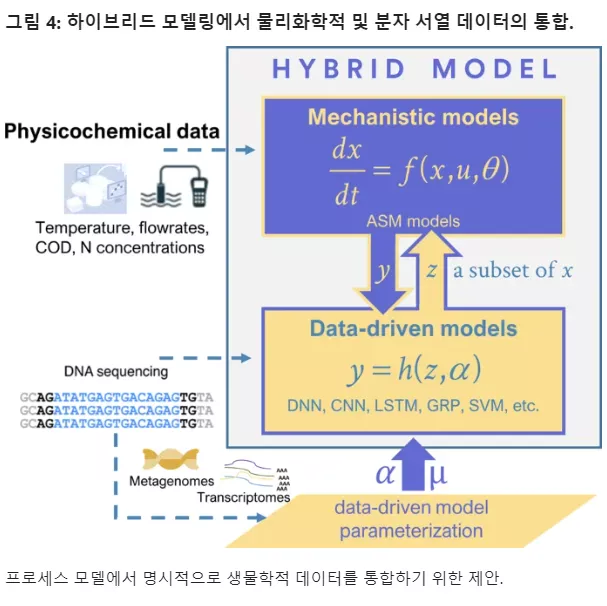
One possible strategy to address this issue is to use ML models that process biological data (e.g., metagenomics) as input and other relevant process data (e.g., NO3 , NO2 and NH4 ) to account for N O emissions through a mass balance for the mechanical process model. This strategy is illustrated in Figure 4.
Here we are talking about, for example, parameterizing gene sequence data and using it to train ML models (such as forward neural networks (DNNs), CNNs, and GANs, among others). Much research in AI techniques and graph theory has shown the possibility of extracting information from 2D and 3D chemical structures (i.e., feature selection) and processes in DNNs to predict some properties of interest (e.g., the biodegradability of various compounds).
Alternatively, it is used in the synthesis of new materials such as zeolites.
In practice, developing these new AI-driven technologies will require ambitious research efforts. Here we call for interdisciplinary collaboration across the community to address some open and fundamental questions about how to achieve thoughtful fusion and integration of data sources and knowledge capabilities.
First and foremost, does incorporating biological data (e.g., metagenomics, meta-transcriptomics, qPCR, FISH, etc.) via ML along with machine models help achieve predictive performance (test data as well as calibration/training data)?
What is the optimal design of a hybrid integration approach (parallel vs. serial, multiplicative vs. embedded at the formation rate of N) to help achieve predictive performance (test data as well as calibration/training data) with ML with mechanical models?
What is the optimal design of a hybrid integration approach (parallel vs. serial, multiplicative vs. embedded at the formation rate of N) to help achieve predictive performance (test data as well as calibration/training data) with ML with mechanical models?
What is the optimal design of a hybrid integration approach (parallel vs. serial, multiply vs. embedded, at a formation rate of N)?2O, at the genus level, the active part of the biomass of different groups is linked to a mechanical model for mass balance, etc.).
Above all, what is the efficient integration of data, ML, and mechanical models for digital applications?
What specific metagenomics data is useful for what modeling purpose?
Should I use metagenomics or metabolomics (protein expression data) and for what modeling purposes?
Because the data extracted from molecular probe technologies is highly heterogeneous and expensive to collect, it typically results in much smaller datasets than can be used for other ML tasks.
These datasets often require functionalization, or as defined by feature engineering, the process of using domain knowledge in the data to create features that help ML algorithms learn better.
In the proposed vision for hybrid modeling in Figure 4, theTherefore, trait extraction will be a key step that needs to be researched and developed to extract useful and relevant traits to transform molecular/metagenomic data from activated sludge plants into a form suitable for current machine/deep learning algorithms.
In the broader literature, feature extraction is a rapidly developing and important field that has already yielded several successful techniques such as extended connectivity fingerprinting, Coulomb matrices, weave functionalization, and graph convolution. Depending on the chosen functionalization, different types of ML models are proposed for molecular datasets, such as message passing neural networks (MPNNs), deep tensor neural networks (DTNNs), directed acyclic graphs (DAGs), and graph convolutional networks.
Graph-based functionalization and neural networks have recently received considerable research attention in cheminformatics and bioinformatics due to their superior performance on molecular ML tasks, as shown in the recent literature. For example, a spatial graph-based molecular representation of amino acid residue pairs has been used to build an AI program developed by DeepMind, the AlfaFold 61 can make 3D protein structure predictions with even greater accuracy than before.
Similarly, the interactions and metabolic functions of microorganisms present in activated sludge systems and their impact on treatment plant performance metrics such as N2O emissions can be studied using graph-based functionalizations derived from metagenomics data, including but not limited to convolution-type neural networks.
These networks have already found use in classifying metagenomics data using paternal distance, defined as a measure of proximity in a phylogenetic tree.
Therefore, these models can be explored to establish a link between the cellular level metabolic activity of microorganisms and their measured impacts at the process plant level. This effort will require domain-specific knowledge of activated sludge microbiology, e.g., the different N2It requires the combination of genetic sequences of key enzymes involved in the metabolism of the O production pathway (e.g., nitrite reduction to NO (mediated by the NirK enzyme), NO reduction to N).
Formulate/define the unique features for the graph neural network model (GCNN) and extract the relevant features/information as input to the hybrid activated sludge model concept given in Figure 4.
This step is precisely the bridge that connects the domain knowledge and expertise of environmental biotechnology and its genomic data with the process engineering/modeling community and their models. In addition to providing a flexible modeling framework that includes genomic data, this neural-based modeling approach addresses a critical limitation of current models.
In fact, the main drawback of current models is that metabolic pathways are assumed a priori and the corresponding model structure is formulated to calibrate the model parameters, which are then fixed and applied to all wastewater treatment plants.
The new hybrid modeling approach uses metagenomics data to determine which pathways are actually present/activated and which pathways are not present/activated in the N2 that contribute to dominant microbial activity.
O phenomena that help ensure the model is valid for each wastewater treatment plant to which it is applied and aligned with baseline microbial community composition and variation.
Therefore, future research will be needed to develop a neural AI methodology tailored to the needs and domain of metagenomics data for use in activated sludge modeling.
Given the recent advances and successful application of GCNNs for chemical property prediction to Generative Adversarial Networks (GANs) in material design, and GANs/reinforcement learning for drug discovery in the wider literature, this interdisciplinary field is being explored to build the foundation for a new area of research.
This provides a rich intellectual foundation for improving modeling (dynamic, steady-state, and meta/ surrogate models) and developing new model-based digital applications, especially for the sustainable operation of WWTPs.
There is certainly a need to join forces with colleagues in environmental biotechnology (high-throughput gene sequencing technologies), wastewater engineering and modeling communities, and computer science applications for AI/Big Data analytics.
ASM has been an invaluable tool that has helped us conceive, design, and operate many wastewater treatment plants.
We argue that it is appropriate to take the field to the next level by utilizing a multidisciplinary research approach that combines new AI techniques to extract features and information from non-traditional heterogeneous data sources, increasing their availability and diversity.
Big data, especially metagenomics data, has never been used for process modeling before. However, much research is needed to utilize ML approaches to integrate biological molecular data.
Thanks to our enhanced biological phenomenon-based approach, we expect to be able to generate previously unknown design, operation, and control solutions to meet the growing needs of WWTPs in new research areas.
Centrifugal dehydrator : Shortcuts















